Ziyi Wu3,4,*,
Yulia Rubanova1,
Rishabh Kabra1,5,
Drew A. Hudson1,
Igor Gilitschenski3,4,
Yusuf Aytar1,
Sjoerd van Steenkiste2,
Kelsey Allen1,
Thomas Kipf1
1Google DeepMind
2Google Research
3University of Toronto
4Vector Institute
5UCL
* Work done while interning at Google
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, “Neural Assets”, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame, which enables learning disentangled appearance and position features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image interface of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
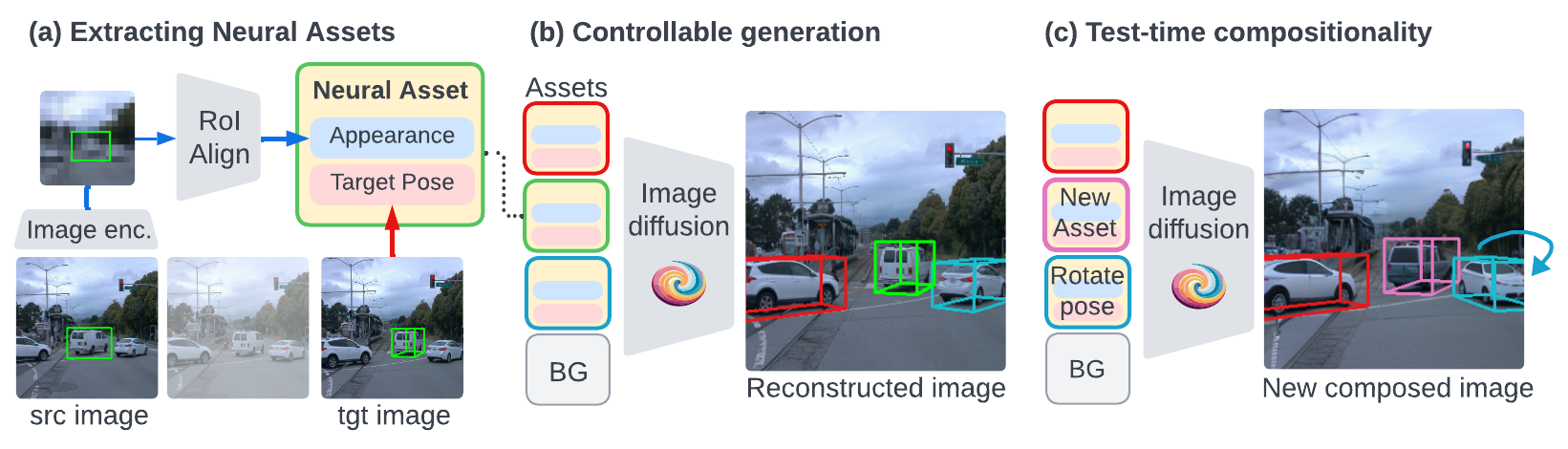
(a) A Neural Asset is an object-centric representation
that consists of an appearance token and a pose token.
(b) To learn disentangled features, we encode appearance
from a source image and object pose (3D bounding box) from a
target image, and train the model to reconstruct the target
image. Therefore, the appearance token is forced to be pose-invariant, i.e.,
it needs to infer the canonical 3D shape of objects.
(c) At testing time, we support versatile 3D-aware object
control such as rotation (blue), and
compositional generation by transferring Neural Assets across scenes
(pink).
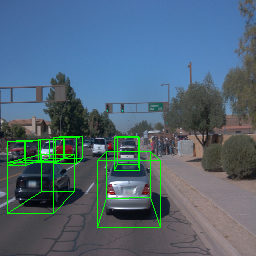
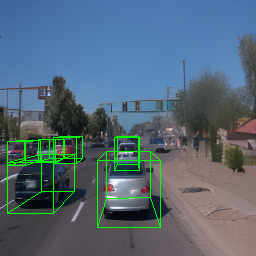
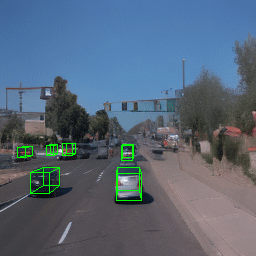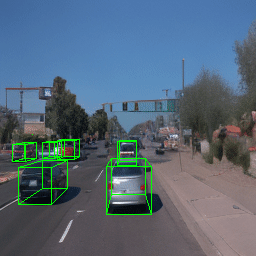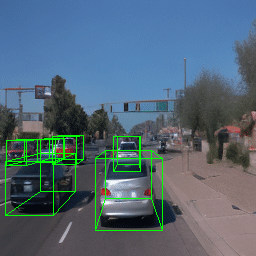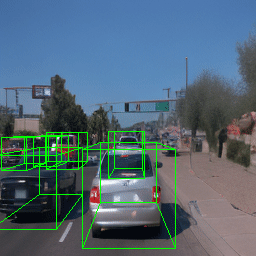
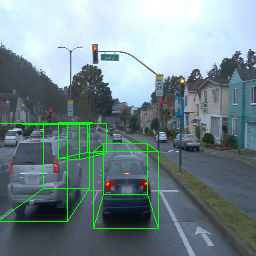
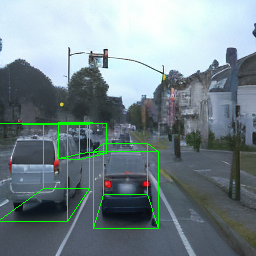
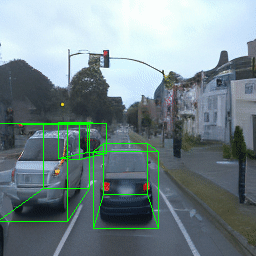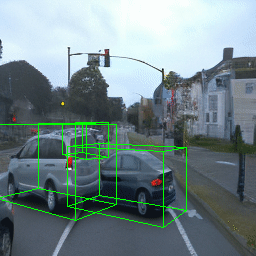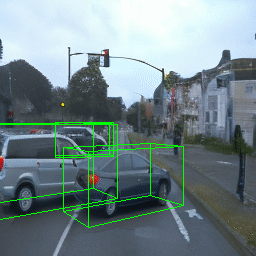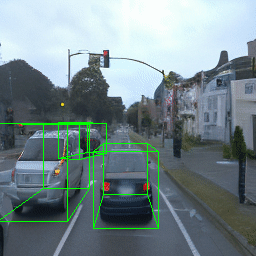
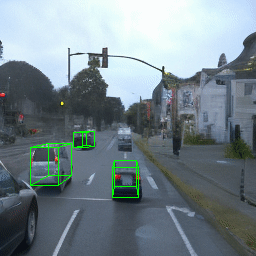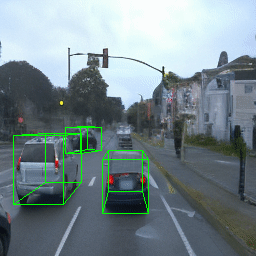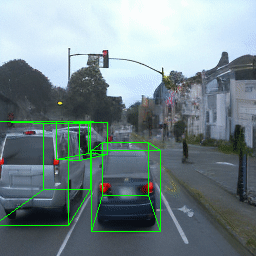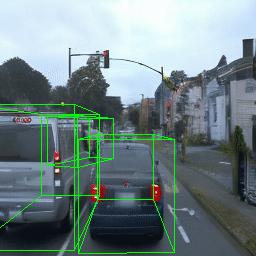
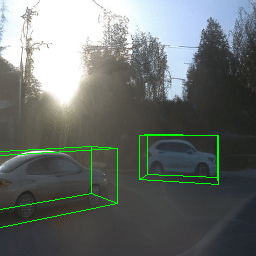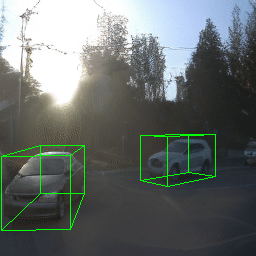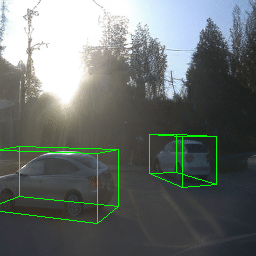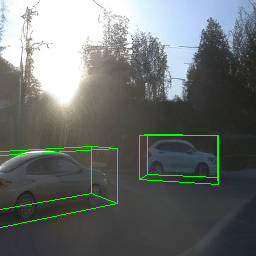
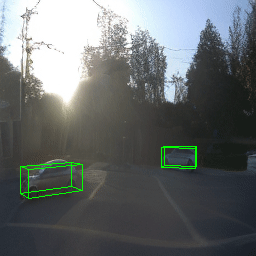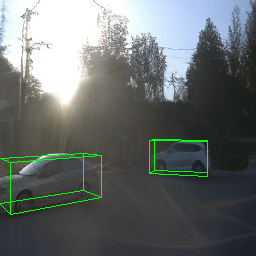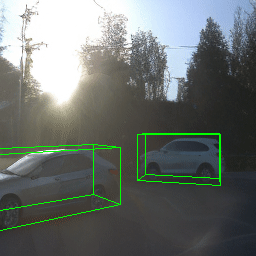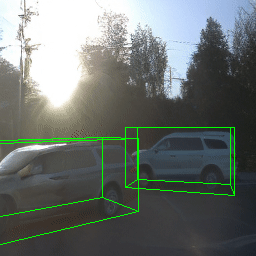
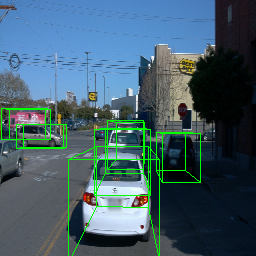
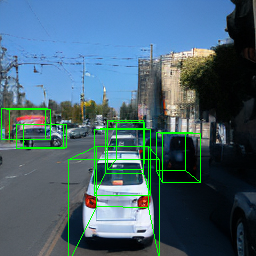
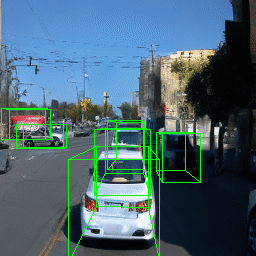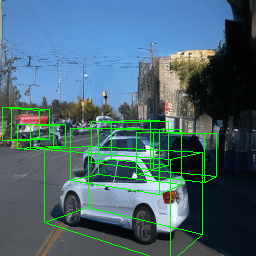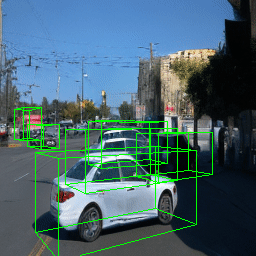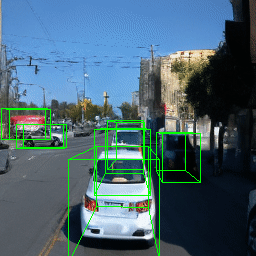
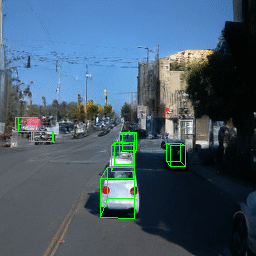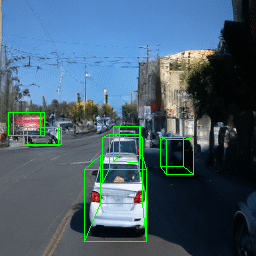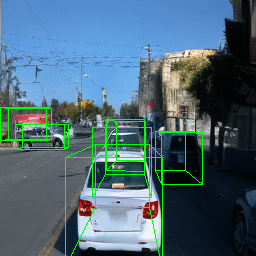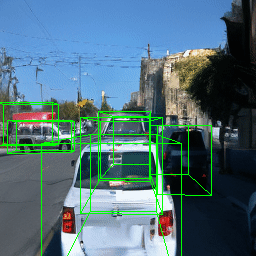
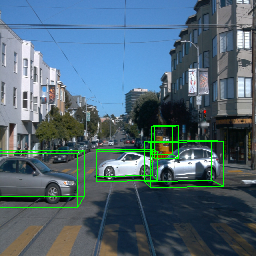
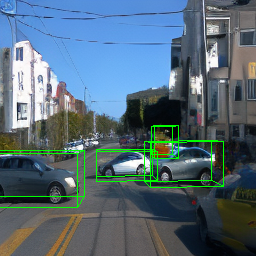
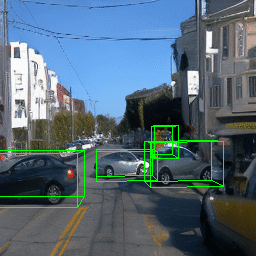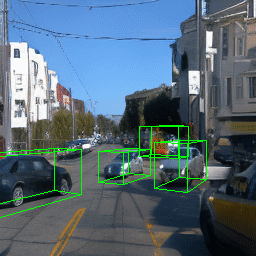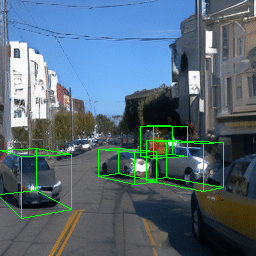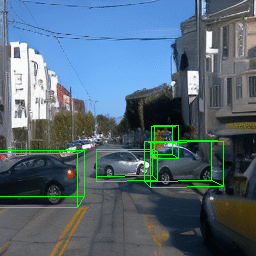
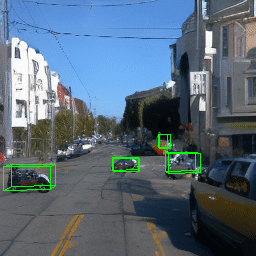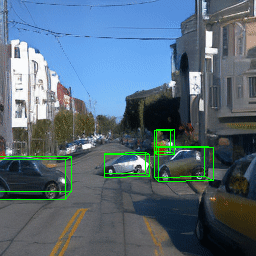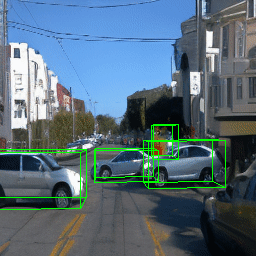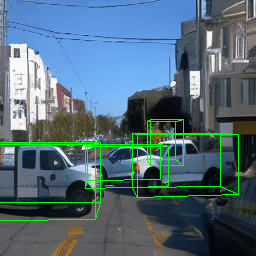
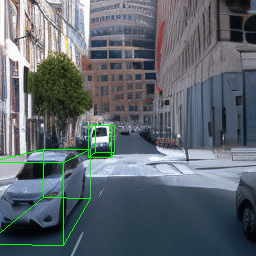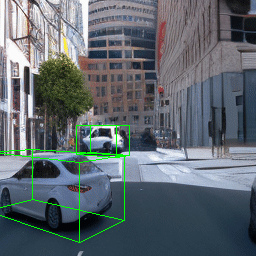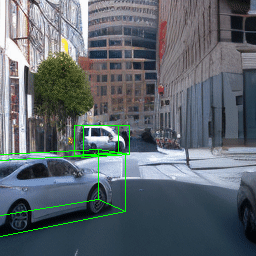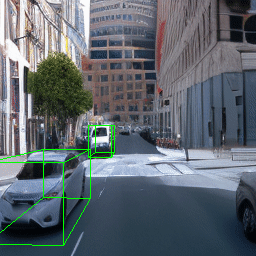
Here, we show multi-object control results on Waymo Open and Objectron datasets. We can easily translate, rotate, and rescale objects by manipulating their 3D bounding boxes. Notice how the model handles occlusions with in-/out-painting and render shadows under new scene configurations.
| Source Image | Reconstruct | Translate | Rotate | Rescale |
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
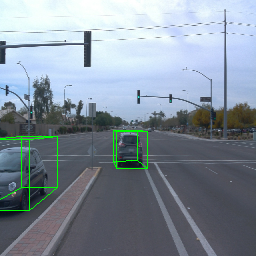
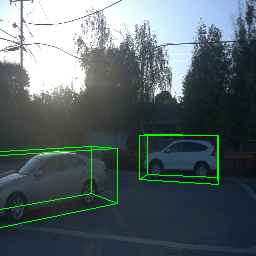
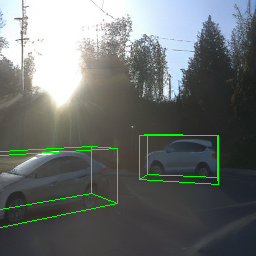
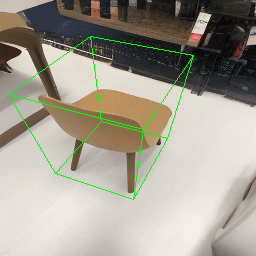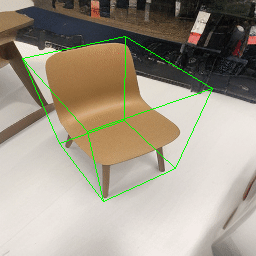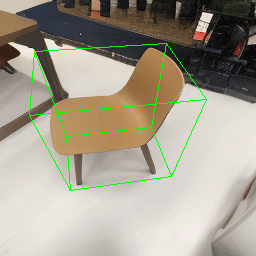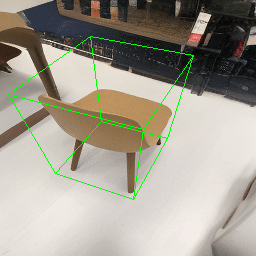
Since Objectron videos only have camera movement (i.e., the objects remain static), the pose of foreground objects is sometimes entangled with global camera pose, as can be seen in the translation results. Nevertheless, in the rotation results, our model is still able to synthesize disentangled object movement.
| Source Image | Reconstruct | Translate | Rotate | Rescale |
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
|
 |
 |
 |
 |
A Neural Asset fully describes the appearance and pose of an object. We can leverage it for compositional generation, e.g., remove, segment out, replace, and transfer objects across scenes.

Since we model scene backgrounds separately, it enables independent control of the global environment. Our generator adapts objects to the new background, e.g., the car lights are turned on in foggy weather or at night. Also, shadows of objects and specular highlights on cars are correctly rendered.

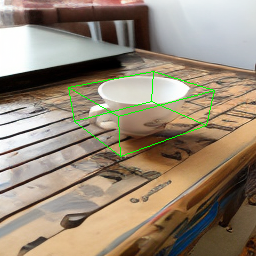
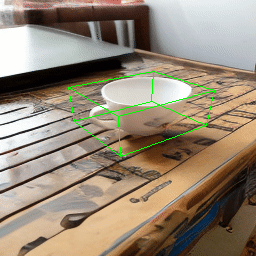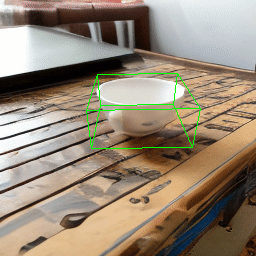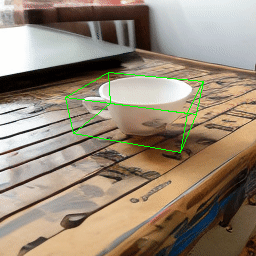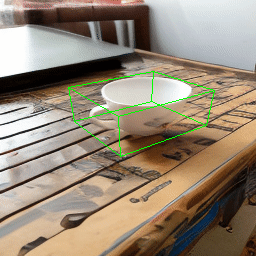
One main failure case of our model is symmetry ambiguity. As can be seen from the following rotation results, the handle of the cup gets flipped when it rotates 180 degree.
| Source Image | Rotate |
|---|---|
 |
 |
 |
 |
[1] Sun, Pei, et al. "Scalability in perception for
autonomous driving: Waymo open dataset." CVPR. 2020.
[2] Ahmadyan, Adel, et al. "Objectron: A large scale dataset of
object-centric videos in the wild with pose annotations." CVPR. 2021.
[3] Rombach, Robin, et al. "High-resolution image synthesis with latent
diffusion models." CVPR. 2022.